介紹 :
各位,在 it 運營中,監(jiān)視服務(wù)器指標(biāo)(例如 cpu/內(nèi)存和磁盤或文件系統(tǒng)的利用率)是一項非常通用的任務(wù),但如果任何指標(biāo)被觸發(fā)為關(guān)鍵指標(biāo),則需要專門人員通過以下方式執(zhí)行一些基本故障排除:登錄服務(wù)器并找出使用的最初原因,如果該人收到多個相同的警報,導(dǎo)致無聊且根本沒有生產(chǎn)力,則他必須多次執(zhí)行該操作。因此,作為一種解決方法,可以開發(fā)一個系統(tǒng),一旦觸發(fā)警報,該系統(tǒng)就會做出反應(yīng),并通過執(zhí)行一些基本的故障排除命令來對這些實例采取行動。只是總結(jié)問題陳述和期望 -
問題陳述:
開發(fā)一個能夠滿足低于預(yù)期的系統(tǒng) -
- 每個 ec2 實例都應(yīng)該由 cloudwatch 監(jiān)控。
- 一旦觸發(fā)警報,就必須有一些東西可以登錄到受影響的 ec2 實例并執(zhí)行一些基本的故障排除命令。
- 然后,創(chuàng)建一個 jira 問題來記錄該事件,并在評論部分添加命令的輸出。
- 然后,發(fā)送一封自動電子郵件,其中提供所有警報詳細信息和 jira 問題詳細信息。
架構(gòu)圖:
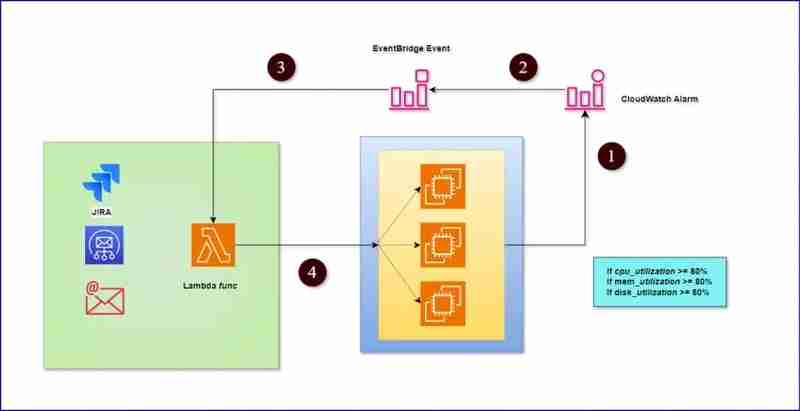
先決條件:
- ec2 實例
- cloudwatch 警報
- eventbridge 規(guī)則
- lambda 函數(shù)
- jira 賬戶
- 簡單的通知服務(wù)
實施步驟:
a. cloudwatch 代理安裝和配置設(shè)置:
打開 systems manager 控制臺并單擊“文檔”
搜索“aws-configureawspackage”文檔并通過提供所需的詳細信息來執(zhí)行。
包名稱 = amazoncloudwatchagent
安裝后,需要根據(jù)配置文件配置 cloudwatch 代理。為此,請執(zhí)行 amazoncloudwatch-manageagent 文檔。另外,請確保 json cloudwatch 配置文件存儲在 ssm 參數(shù)中。
一旦您看到指標(biāo)正在向 cloudwatch 控制臺報告,請為 cpu 和內(nèi)存利用率等創(chuàng)建警報。b.設(shè)置eventbridge規(guī)則:
為了跟蹤警報狀態(tài)的變化,這里,我們稍微定制了模式來跟蹤警報狀態(tài)從 ok 到 alarm 的變化,而不是反向變化。然后,將此規(guī)則添加到 lambda 函數(shù)作為觸發(fā)器。
{
"source": ["aws.cloudwatch"],
"detail-type": ["cloudwatch alarm state change"],
"detail": {
"state": {
"value": ["alarm"]
},
"previousstate": {
"value": ["ok"]
}
}
}
- c.創(chuàng)建 lambda 函數(shù)以在 jira 中發(fā)送電子郵件和記錄事件: 此 lambda 函數(shù)是為由 eventbridge 規(guī)則觸發(fā)的多個活動創(chuàng)建的,并作為使用 aws sdk(boto3) 添加的目標(biāo) sns 主題。一旦觸發(fā) eventbridge 規(guī)則,就會將 json 事件內(nèi)容發(fā)送到 lambda,該函數(shù)通過該函數(shù)捕獲多個詳細信息以不同的方式進行處理。 到目前為止,我們已經(jīng)研究了兩種類型的警報 - i。 cpu 利用率和 ii.內(nèi)存利用率。一旦這兩個警報中的任何一個被觸發(fā)并且警報狀態(tài)從 ok 更改為 alarm,就會觸發(fā) eventbridge,這也會觸發(fā) lambda 函數(shù)來執(zhí)行表單代碼中提到的那些任務(wù)。
lambda 先決條件:
我們需要導(dǎo)入以下模塊才能使代碼正常工作 -
- >> 操作系統(tǒng)
- >> 系統(tǒng)
- >> json
- >> boto3
- >> 時間
- >> 請求
注意: 從上面的模塊中,除了“requests”模塊之外,其余的都默認在 lambda 底層基礎(chǔ)設(shè)施中下載。 lambda 不支持直接導(dǎo)入“requests”模塊。因此,首先,通過執(zhí)行以下命令將請求模塊安裝在本地計算機(筆記本電腦)的文件夾中 -
pip3 install requests -t <directory path> --no-user </directory>
_之后,這將被下載到您執(zhí)行上述命令的文件夾或您想要存儲模塊源代碼的文件夾中,這里我希望 lambda 代碼正在您的本地計算機中準(zhǔn)備。如果是,則使用 module.txt 創(chuàng)建整個 lambda 源代碼的 zip 文件。之后,將 zip 文件上傳到 lambda 函數(shù)。
所以,我們在這里執(zhí)行以下兩個場景 -
1. cpu 利用率 - 如果觸發(fā) cpu 利用率警報,則 lambda 函數(shù)需要獲取實例并登錄到該實例并執(zhí)行前 5 個高消耗進程。然后,它將創(chuàng)建一個 jira 問題并在評論部分添加流程詳細信息。同時,它將發(fā)送一封電子郵件,其中包含警報詳細信息和 jira 問題詳細信息以及流程輸出。
2.內(nèi)存利用率 - 與上面相同的方法
現(xiàn)在,讓我重新構(gòu)建 lambda 應(yīng)該執(zhí)行的任務(wù)細節(jié) -
- 登錄實例
- 執(zhí)行基本故障排除步驟。
- 創(chuàng)建 jira 問題
- 向收件人發(fā)送包含所有詳細信息的電子郵件
場景 1:當(dāng)警報狀態(tài)從 ok 更改為 alarm 時
第一組(定義cpu和內(nèi)存函數(shù)):
################# importing required modules ################
############################################################
import json
import boto3
import time
import os
import sys
sys.path.append('./python') ## this will add requests module along with all dependencies into this script
import requests
from requests.auth import httpbasicauth
################## calling aws services ###################
###########################################################
ssm = boto3.client('ssm')
sns_client = boto3.client('sns')
ec2 = boto3.client('ec2')
################## defining blank variable ################
###########################################################
cpu_process_op = ''
mem_process_op = ''
issueid = ''
issuekey = ''
issuelink = ''
################# function for cpu utilization ################
###############################################################
def cpu_utilization(instanceid, metric_name, previous_state, current_state):
global cpu_process_op
if previous_state == 'ok' and current_state == 'alarm':
command = 'ps -eo user,pid,ppid,cmd,%mem,%cpu --sort=-%cpu | head -5'
print(f'impacted instance id is : {instanceid}, metric name: {metric_name}')
# start a session
print(f'starting session to {instanceid}')
response = ssm.send_command(instanceids = [instanceid], documentname="aws-runshellscript", parameters={'commands': [command]})
command_id = response['command']['commandid']
print(f'command id: {command_id}')
# retrieve the command output
time.sleep(4)
output = ssm.get_command_invocation(commandid=command_id, instanceid=instanceid)
print('please find below output -\n', output['standardoutputcontent'])
cpu_process_op = output['standardoutputcontent']
else:
print('none')
################# function for memory utilization ################
###############################################################
def mem_utilization(instanceid, metric_name, previous_state, current_state):
global mem_process_op
if previous_state == 'ok' and current_state == 'alarm':
command = 'ps -eo user,pid,ppid,cmd,%mem,%cpu --sort=-%mem | head -5'
print(f'impacted instance id is : {instanceid}, metric name: {metric_name}')
# start a session
print(f'starting session to {instanceid}')
response = ssm.send_command(instanceids = [instanceid], documentname="aws-runshellscript", parameters={'commands': [command]})
command_id = response['command']['commandid']
print(f'command id: {command_id}')
# retrieve the command output
time.sleep(4)
output = ssm.get_command_invocation(commandid=command_id, instanceid=instanceid)
print('please find below output -\n', output['standardoutputcontent'])
mem_process_op = output['standardoutputcontent']
else:
print('none')
第二組(創(chuàng)建 jira 問題):
################## create jira issue ################
#####################################################
def create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val):
## create issue ##
url ='https://<your-user-name>.atlassian.net//rest/api/2/issue'
username = os.environ['username']
api_token = os.environ['token']
project = 'anirbanspace'
issue_type = 'incident'
assignee = os.environ['username']
summ_metric = '%cpu utilization' if 'cpu' in metric_name else '%memory utilization' if 'mem' in metric_name else '%filesystem utilization' if metric_name == 'disk_used_percent' else none
metric_val = metric_val
summary = f'client | {account} | {instanceid} | {summ_metric} | metric value: {metric_val}'
description = f'client: company\naccount: {account}\nregion: {region}\ninstanceid = {instanceid}\ntimestamp = {timestamp}\ncurrent state: {current_state}\nprevious state = {previous_state}\nmetric value = {metric_val}'
issue_data = {
"fields": {
"project": {
"key": "scrum"
},
"summary": summary,
"description": description,
"issuetype": {
"name": issue_type
},
"assignee": {
"name": assignee
}
}
}
data = json.dumps(issue_data)
headers = {
"accept": "application/json",
"content-type": "application/json"
}
auth = httpbasicauth(username, api_token)
response = requests.post(url, headers=headers, auth=auth, data=data)
global issueid
global issuekey
global issuelink
issueid = response.json().get('id')
issuekey = response.json().get('key')
issuelink = response.json().get('self')
################ add comment to above created jira issue ###################
output = cpu_process_op if metric_name == 'cpuutilization' else mem_process_op if metric_name == 'mem_used_percent' else none
comment_api_url = f"{url}/{issuekey}/comment"
add_comment = requests.post(comment_api_url, headers=headers, auth=auth, data=json.dumps({"body": output}))
## check the response
if response.status_code == 201:
print("issue created successfully. issue key:", response.json().get('key'))
else:
print(f"failed to create issue. status code: {response.status_code}, response: {response.text}")
</your-user-name>
第三組(發(fā)送電子郵件):
################## send an email ################
#################################################
def send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink):
### define a dictionary of custom input ###
metric_list = {'mem_used_percent': 'memory', 'disk_used_percent': 'disk', 'cpuutilization': 'cpu'}
### conditions ###
if previous_state == 'ok' and current_state == 'alarm' and metric_name in list(metric_list.keys()):
metric_msg = metric_list[metric_name]
output = cpu_process_op if metric_name == 'cpuutilization' else mem_process_op if metric_name == 'mem_used_percent' else none
print('this is output', output)
email_body = f"hi team, \n\nplease be informed that {metric_msg} utilization is high for the instanceid {instanceid}. please find below more information \n\nalarm details:\nmetricname = {metric_name}, \naccount = {account}, \ntimestamp = {timestamp}, \nregion = {region}, \ninstanceid = {instanceid}, \ncurrentstate = {current_state}, \nreason = {current_reason}, \nmetricvalue = {metric_val}, \nthreshold = 80.00 \n\nprocessoutput: \n{output}\nincident deatils:\nissueid = {issueid}, \nissuekey = {issuekey}, \nlink = {issuelink}\n\nregards,\nanirban das,\nglobal cloud operations team"
res = sns_client.publish(
topicarn = os.environ['snsarn'],
subject = f'high {metric_msg} utilization alert : {instanceid}',
message = str(email_body)
)
print('mail has been sent') if res else print('email not sent')
else:
email_body = str(0)
第四組(調(diào)用 lambda 處理函數(shù)):
################## lambda handler function ################
###########################################################
def lambda_handler(event, context):
instanceid = event['detail']['configuration']['metrics'][0]['metricstat']['metric']['dimensions']['instanceid']
metric_name = event['detail']['configuration']['metrics'][0]['metricstat']['metric']['name']
account = event['account']
timestamp = event['time']
region = event['region']
current_state = event['detail']['state']['value']
current_reason = event['detail']['state']['reason']
previous_state = event['detail']['previousstate']['value']
previous_reason = event['detail']['previousstate']['reason']
metric_val = json.loads(event['detail']['state']['reasondata'])['evaluateddatapoints'][0]['value']
##### function calling #####
if metric_name == 'cpuutilization':
cpu_utilization(instanceid, metric_name, previous_state, current_state)
create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val)
send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink)
elif metric_name == 'mem_used_percent':
mem_utilization(instanceid, metric_name, previous_state, current_state)
create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val)
send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink)
else:
none
報警郵件截圖:
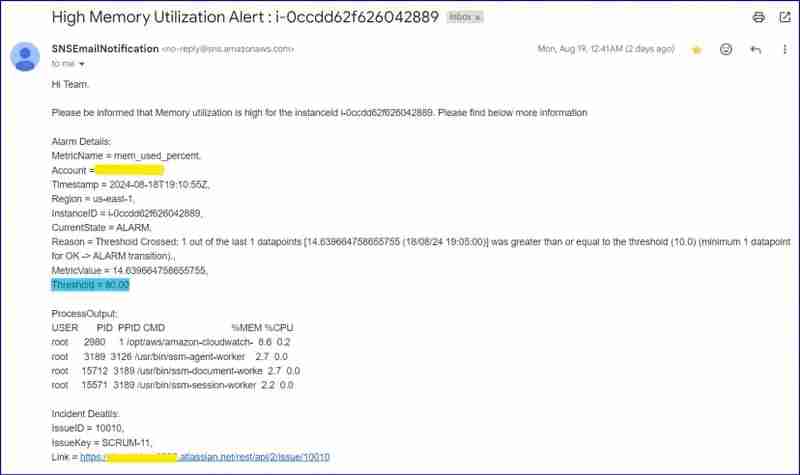
注意:在理想情況下,閾值是 80%,但為了測試我將其更改為 10%。請看原因。
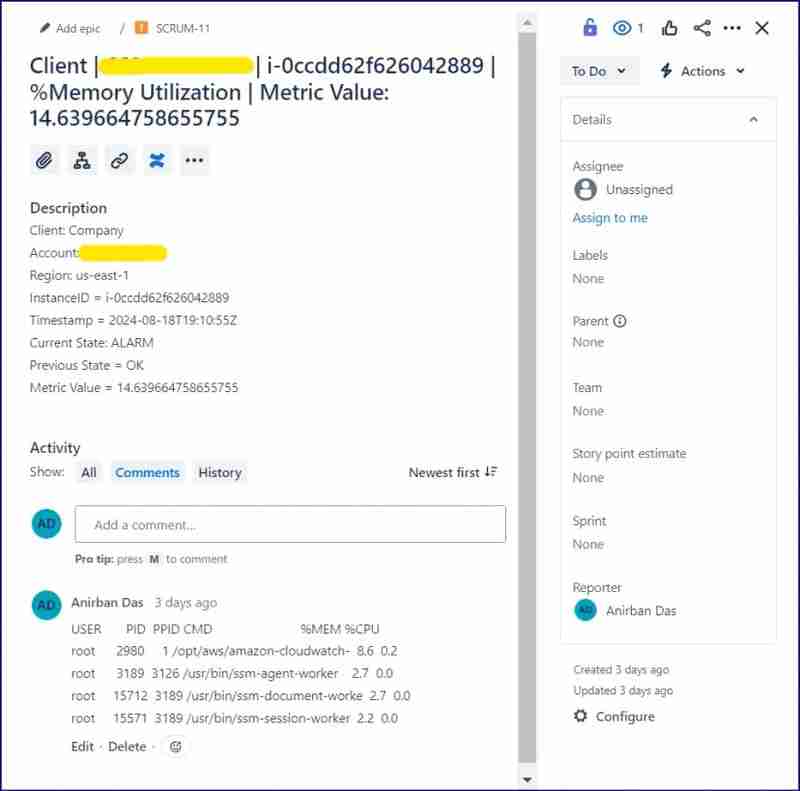
警報 jira 問題:
場景 2:當(dāng)警報狀態(tài)從“正常”更改為“數(shù)據(jù)不足”時
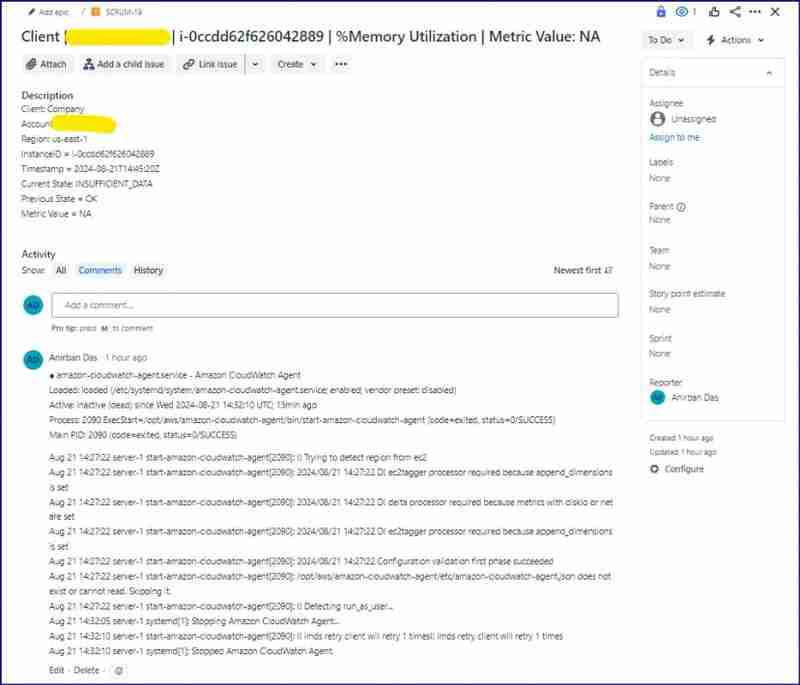
在這種情況下,如果未捕獲任何服務(wù)器 cpu 或內(nèi)存利用率指標(biāo)數(shù)據(jù),則警報狀態(tài)將從 ok 更改為 insufficient_data。可以通過兩種方式實現(xiàn)此狀態(tài) - a.) 如果服務(wù)器處于停止?fàn)顟B(tài) b.) 如果 cloudwatch 代理未運行或進入死亡狀態(tài)。
因此,根據(jù)下面的腳本,您將能夠看到,當(dāng) cpu 或內(nèi)存利用率警報狀態(tài)獲取的數(shù)據(jù)不足時,lambda 將首先檢查實例是否處于運行狀態(tài)。如果實例處于運行狀態(tài),那么它將登錄并檢查 cloudwatch 代理狀態(tài)。發(fā)布后,它將創(chuàng)建一個 jira 問題并在 jira 問題的評論部分發(fā)布代理狀態(tài)。之后,它將發(fā)送一封包含警報詳細信息和代理狀態(tài)的電子郵件。
完整代碼:
################# Importing Required Modules ################
############################################################
import json
import boto3
import time
import os
import sys
sys.path.append('./python') ## This will add requests module along with all dependencies into this script
import requests
from requests.auth import HTTPBasicAuth
################## Calling AWS Services ###################
###########################################################
ssm = boto3.client('ssm')
sns_client = boto3.client('sns')
ec2 = boto3.client('ec2')
################## Defining Blank Variable ################
###########################################################
cpu_process_op = ''
mem_process_op = ''
issueid = ''
issuekey = ''
issuelink = ''
################# Function for CPU Utilization ################
###############################################################
def cpu_utilization(instanceid, metric_name, previous_state, current_state):
global cpu_process_op
if previous_state == 'OK' and current_state == 'INSUFFICIENT_DATA':
ec2_status = ec2.describe_instance_status(InstanceIds=[instanceid,])['InstanceStatuses'][0]['InstanceState']['Name']
if ec2_status == 'running':
command = 'systemctl status amazon-cloudwatch-agent;sleep 3;systemctl restart amazon-cloudwatch-agent'
print(f'Impacted Instance ID is : {instanceid}, Metric Name: {metric_name}')
# Start a session
print(f'Starting session to {instanceid}')
response = ssm.send_command(InstanceIds = [instanceid], DocumentName="AWS-RunShellScript", Parameters={'commands': [command]})
command_id = response['Command']['CommandId']
print(f'Command ID: {command_id}')
# Retrieve the command output
time.sleep(4)
output = ssm.get_command_invocation(CommandId=command_id, InstanceId=instanceid)
print('Please find below output -\n', output['StandardOutputContent'])
cpu_process_op = output['StandardOutputContent']
else:
cpu_process_op = f'Instance current status is {ec2_status}. Not able to reach out!!'
print(f'Instance current status is {ec2_status}. Not able to reach out!!')
else:
print('None')
################# Function for Memory Utilization ################
###############################################################
def mem_utilization(instanceid, metric_name, previous_state, current_state):
global mem_process_op
if previous_state == 'OK' and current_state == 'INSUFFICIENT_DATA':
ec2_status = ec2.describe_instance_status(InstanceIds=[instanceid,])['InstanceStatuses'][0]['InstanceState']['Name']
if ec2_status == 'running':
command = 'systemctl status amazon-cloudwatch-agent'
print(f'Impacted Instance ID is : {instanceid}, Metric Name: {metric_name}')
# Start a session
print(f'Starting session to {instanceid}')
response = ssm.send_command(InstanceIds = [instanceid], DocumentName="AWS-RunShellScript", Parameters={'commands': [command]})
command_id = response['Command']['CommandId']
print(f'Command ID: {command_id}')
# Retrieve the command output
time.sleep(4)
output = ssm.get_command_invocation(CommandId=command_id, InstanceId=instanceid)
print('Please find below output -\n', output['StandardOutputContent'])
mem_process_op = output['StandardOutputContent']
print(mem_process_op)
else:
mem_process_op = f'Instance current status is {ec2_status}. Not able to reach out!!'
print(f'Instance current status is {ec2_status}. Not able to reach out!!')
else:
print('None')
################## Create JIRA Issue ################
#####################################################
def create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val):
## Create Issue ##
url ='https://<your-user-name>.atlassian.net//rest/api/2/issue'
username = os.environ['username']
api_token = os.environ['token']
project = 'AnirbanSpace'
issue_type = 'Incident'
assignee = os.environ['username']
summ_metric = '%CPU Utilization' if 'CPU' in metric_name else '%Memory Utilization' if 'mem' in metric_name else '%Filesystem Utilization' if metric_name == 'disk_used_percent' else None
metric_val = metric_val
summary = f'Client | {account} | {instanceid} | {summ_metric} | Metric Value: {metric_val}'
description = f'Client: Company\nAccount: {account}\nRegion: {region}\nInstanceID = {instanceid}\nTimestamp = {timestamp}\nCurrent State: {current_state}\nPrevious State = {previous_state}\nMetric Value = {metric_val}'
issue_data = {
"fields": {
"project": {
"key": "SCRUM"
},
"summary": summary,
"description": description,
"issuetype": {
"name": issue_type
},
"assignee": {
"name": assignee
}
}
}
data = json.dumps(issue_data)
headers = {
"Accept": "application/json",
"Content-Type": "application/json"
}
auth = HTTPBasicAuth(username, api_token)
response = requests.post(url, headers=headers, auth=auth, data=data)
global issueid
global issuekey
global issuelink
issueid = response.json().get('id')
issuekey = response.json().get('key')
issuelink = response.json().get('self')
################ Add Comment To Above Created JIRA Issue ###################
output = cpu_process_op if metric_name == 'CPUUtilization' else mem_process_op if metric_name == 'mem_used_percent' else None
comment_api_url = f"{url}/{issuekey}/comment"
add_comment = requests.post(comment_api_url, headers=headers, auth=auth, data=json.dumps({"body": output}))
## Check the response
if response.status_code == 201:
print("Issue created successfully. Issue key:", response.json().get('key'))
else:
print(f"Failed to create issue. Status code: {response.status_code}, Response: {response.text}")
################## Send An Email ################
#################################################
def send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink):
### Define a dictionary of custom input ###
metric_list = {'mem_used_percent': 'Memory', 'disk_used_percent': 'Disk', 'CPUUtilization': 'CPU'}
### Conditions ###
if previous_state == 'OK' and current_state == 'INSUFFICIENT_DATA' and metric_name in list(metric_list.keys()):
metric_msg = metric_list[metric_name]
output = cpu_process_op if metric_name == 'CPUUtilization' else mem_process_op if metric_name == 'mem_used_percent' else None
email_body = f"Hi Team, \n\nPlease be informed that {metric_msg} utilization alarm state has been changed to {current_state} for the instanceid {instanceid}. Please find below more information \n\nAlarm Details:\nMetricName = {metric_name}, \n Account = {account}, \nTimestamp = {timestamp}, \nRegion = {region}, \nInstanceID = {instanceid}, \nCurrentState = {current_state}, \nReason = {current_reason}, \nMetricValue = {metric_val}, \nThreshold = 80.00 \n\nProcessOutput = \n{output}\nIncident Deatils:\nIssueID = {issueid}, \nIssueKey = {issuekey}, \nLink = {issuelink}\n\nRegards,\nAnirban Das,\nGlobal Cloud Operations Team"
res = sns_client.publish(
TopicArn = os.environ['snsarn'],
Subject = f'Insufficient {metric_msg} Utilization Alarm : {instanceid}',
Message = str(email_body)
)
print('Mail has been sent') if res else print('Email not sent')
else:
email_body = str(0)
################## Lambda Handler Function ################
###########################################################
def lambda_handler(event, context):
instanceid = event['detail']['configuration']['metrics'][0]['metricStat']['metric']['dimensions']['InstanceId']
metric_name = event['detail']['configuration']['metrics'][0]['metricStat']['metric']['name']
account = event['account']
timestamp = event['time']
region = event['region']
current_state = event['detail']['state']['value']
current_reason = event['detail']['state']['reason']
previous_state = event['detail']['previousState']['value']
previous_reason = event['detail']['previousState']['reason']
metric_val = 'NA'
##### function calling #####
if metric_name == 'CPUUtilization':
cpu_utilization(instanceid, metric_name, previous_state, current_state)
create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val)
send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink)
elif metric_name == 'mem_used_percent':
mem_utilization(instanceid, metric_name, previous_state, current_state)
create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val)
send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink)
else:
None
</your-user-name>
數(shù)據(jù)不足郵件截圖:
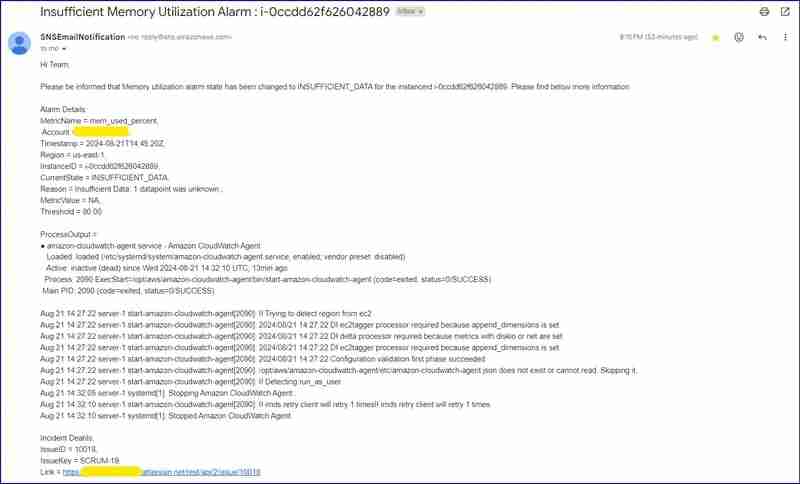
數(shù)據(jù)不足jira問題:
結(jié)論 :
在本文中,我們測試了有關(guān) cpu 和內(nèi)存利用率的場景,但是我們可以在很多指標(biāo)上配置自動事件和自動電子郵件功能,這將減少監(jiān)控和創(chuàng)建事件等方面的大量工作。 。該解決方案為我們提供了進一步推進的初步方法,但可以肯定的是,還可以有其他可能性來實現(xiàn)這一目標(biāo)。我相信你們都會理解我們?nèi)绾闻ψ屵@一切產(chǎn)生關(guān)聯(lián)。如果您喜歡這篇文章或有任何其他建議,請點贊和評論,以便我們可以在接下來的文章中補充。 ??
謝謝!!
阿尼班·達斯
以上就是使用 EventBridge 和 Lambda 進行自動故障排除和 ITSM 系統(tǒng)的詳細內(nèi)容,更多請關(guān)注愛掏網(wǎng) - it200.com其它相關(guān)文章!