MapReduce是一種編程模型,用于大規模數據集(大于1TB)的并行運算,Hadoop MapReduce提供了一個易于編程的框架,該框架可在大型集群(上千節點)上可靠、容錯地快速處理大量數據,下面將詳細解析MapReduce的基本原理,并使用小標題和單元表格來清晰地展示其核心概念:
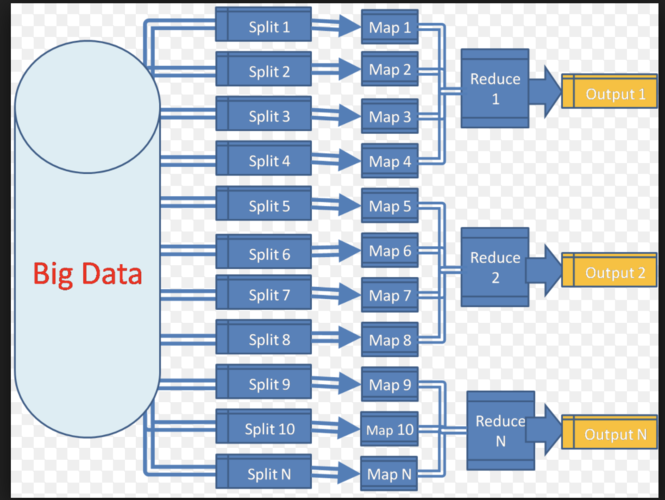

1、MapReduce
概念理解:MapReduce是一個編程模型,分為兩個基本操作——Map和Reduce,它允許開發人員編寫業務邏輯代碼,與Hadoop自帶組件整合,形成完整的分布式運算程序。
數據處理流程:Map負責數據的映射和過濾,而Reduce負責數據的聚合和歸納,這兩個過程合作完成大數據的處理任務。
2、Map函數詳解
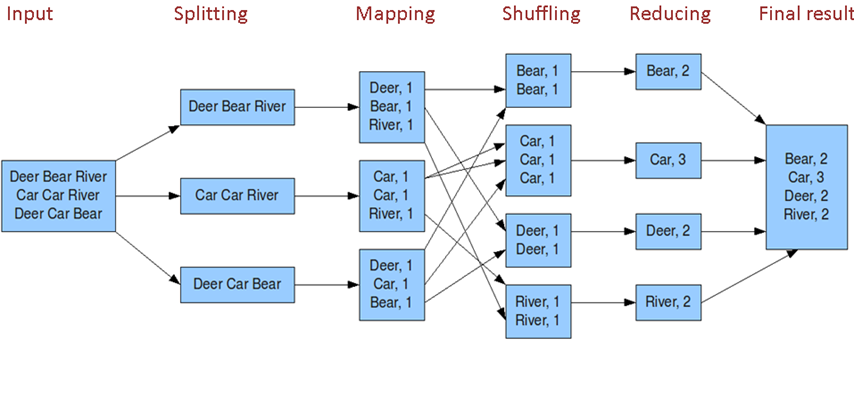
映射過程:在Map階段,輸入數據被拆分成小塊,每塊分別進行Map函數處理,Map函數通常用來執行數據變換,比如數據清洗或轉換格式。
過濾功能:Map函數除了進行數據變換外,還負責數據的初步篩選,過濾掉不必要的信息,只保留符合要求的數據項。
3、Reduce函數詳解
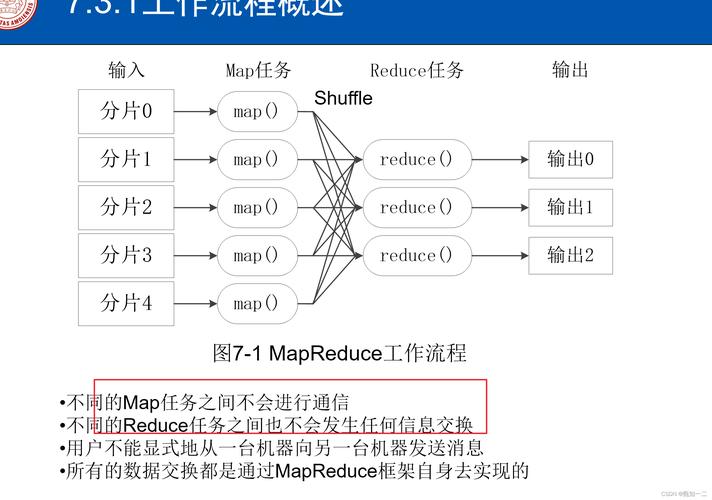
聚合過程:經過Map處理的數據項,會通過Shuffle過程傳遞給Reduce,Reduce函數接著對數據進行匯總,例如統計相同鍵值的數據項數量或進行其他形式的聚合操作。
歸納歸納:Reduce將處理結果輸出,這個結果往往是更精煉的數據集或是基于原始數據集合的最終計算結果。
4、MapReduce工作流程
分而治之的策略:MapReduce采用“分而治之”的策略,先將大數據集切分成小塊,分別處理(Map),再將中間結果合并得到最終結果(Reduce)。
并行化處理:MapReduce框架能夠自動并行處理多個Map和Reduce任務,從而顯著提高大規模數據處理的速度。
5、數據流和控制流
數據流:MapReduce作業的數據流從輸入數據開始,經過Map處理,通過Shuffle排序,最終進入Reduce處理,生成輸出結果。
控制流:控制流描述了作業的調度和監控過程,包括作業提交、狀態跟蹤和錯誤處理等。
6、容錯性和可靠性
容錯機制:MapReduce框架設計了健壯的容錯機制,能夠自動重新執行失敗的Map或Reduce任務。
數據備份:系統會默認對數據進行備份,以防數據丟失導致的任務失敗。
7、適用場景與優勢
適用場景:MapReduce適用于批量處理大規模數據集,如日志分析、數據挖掘等場景。
性能優勢:由于并行處理的特性,MapReduce能夠在數分鐘內處理TB級別的數據,相比傳統數據庫處理方法大大節省了時間成本。
8、實際應用中的優化技巧
代碼優化:合理設計Map和Reduce函數可以提升數據處理效率,減少不必要的數據移動和復制。
配置調整:根據集群的特點和作業的需求,調整Hadoop配置參數,如內存分配、并發任務數量等,可以進一步優化性能。
隨著對MapReduce原理的深入理解,還需注意以下幾點以更好地應用于實踐:
確保在設計Map和Reduce函數時充分考慮數據的局部性,以減少網絡傳輸開銷。
適當地設置數據塊大小和備份數量,以平衡存儲成本和容錯需求。
監控和調試工具對于定位問題和優化作業性能至關重要,不要忽視它們的作用。
MapReduce作為一個高效的數據處理模型,其強大的并行處理能力和容錯機制使它成為大數據分析領域的核心工具,掌握其基本原理及優化技巧對于從事相關領域的專業人士至關重要。